


최근 #AI 연구들 나오는게 패턴이 다 거기서 거기라 (개개의 의미있음과는 별개로) 좀 식상한감이 없잖았는데.. 간만에 진짜 재밌는 논문을 하나 읽었습니다. ACL 2023에 발표된 논문인 것 같은데 인사이트가 매우 근사하네요.
전문: https://aclanthology.org/2023.findings-acl.426.pdf
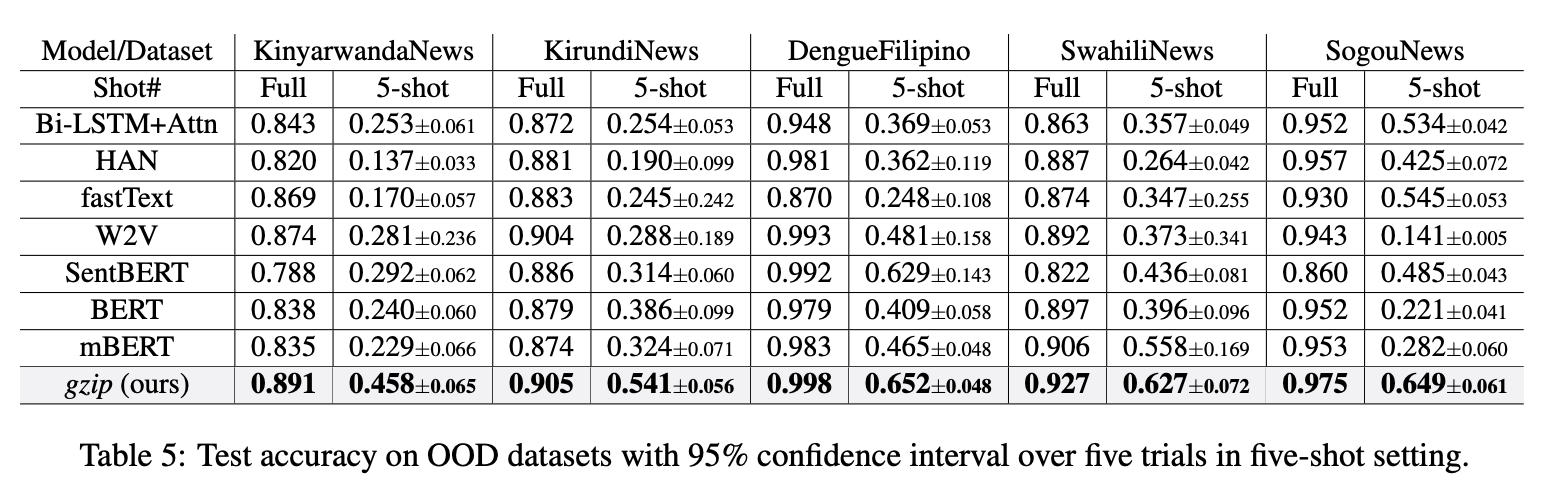
저자들은 굉장히 단순한 #kNN (k-최근접 이웃) 알고리즘을 써서 #딥러닝 + #트랜스포머 기반의 모델들을 (특히 기존의 sota였던 #BERT 를) 능가하는 텍스트 분류 모델을 만들어 냈습니다. 그 아이디어가 진짜 기가 막힌데.. 압축 알고리즘을 핵심 거리측도로 사용했네요.
이게 뭔말이냐면
: 텍스트 A만 압축 → 별도로 A와 B를 같이 압축 → 사이즈가 비슷할수록 A와 B는 '가깝다'!
구현도 이해도 무척 직관적입니다. 그리고 *당연히* 딥러닝보다 훨씬 리소스를 덜먹습니다. 요즘 기준으로 BERT가 그리 무거운 모델은 아닙니다만 대규모 분류작업이 줄 이점을 생각하면 이 연구의 시사점은 큽니다.



 려
려











